Normalization
Before we learn about Batch normalization lets see what is Normalization. It is technique of transforming the data to put all the data points on the same scale.
A typical normalization process consists of scaling numerical data down to be on a scale from zero to one.
We use Normalization to avoid to have some numerical data very high and some data very low.
For example if we have feature that represent age and other feature that represent number of driven kilometers we can see that these two data will not be on the same scale and we use Normalization to put this data on common scale.
Batch Normalization
Batch normalization is normalization technique used in Deep learning. It is applied to layers that we choose within our network. With normalization we process data before being passed to the input layer but with Batch normalization we process output of layers that we choose.
Batch normalization makes it so that the weights within the network don’t become imbalanced with extremely high or low values. With Batch normalization we avoid Exploding gradient problem (very large updates to neural network model weights during training which leads to unstable neural network) which may be caused by large input values in layers.
General purpose of Batch normalization is to speed up training and make neural network more stable.
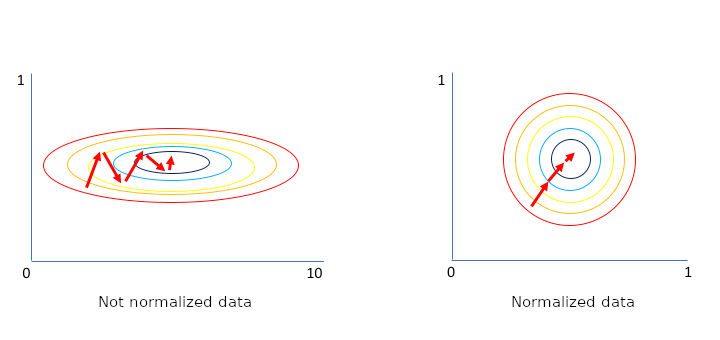
In picture above we see that when data is normalized then it require less steps to find optimal result.
This Normalization is called Batch normalization because it occurs on a per-batch basis.
Mathematical Implementation
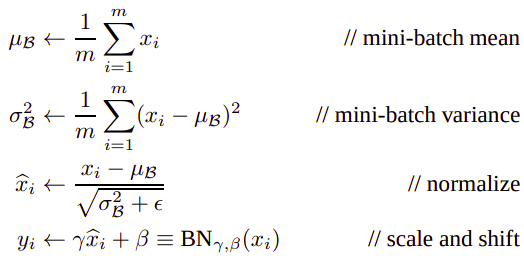
µB - mini-batch mean
σ^2B - mini-batch variance
x_hat - normalized x
y - scaled and shifted value that represent final batch normalization result
γ - trainabale parameter
β - trainabale parameterWe could normalize values before or after activation function but often better result is when we normalize values before activation function.
Programming Implementation
Keras:
tf.keras.layers.BatchNormalization(
axis=-1, momentum=0.99, epsilon=0.001, center=True, scale=True,
beta_initializer='zeros', gamma_initializer='ones',
moving_mean_initializer='zeros', moving_variance_initializer='ones',
beta_regularizer=None, gamma_regularizer=None, beta_constraint=None,
gamma_constraint=None, renorm=False, renorm_clipping=None, renorm_momentum=0.99,
fused=None, trainable=True, virtual_batch_size=None, adjustment=None, name=None,
**kwargs
)https://www.tensorflow.org/api_docs/python/tf/keras/layers/BatchNormalization
We can also use Adam or RMSprop or momentum in order to update the parameters Beta and Gamma for Batch normalization layer.
In programming implementation like in Keras we just add Batch normalization layer in our model to implement Batch normalization.
Thanks for reading this post.
References
- Coursera. 2020. Normalizing Activations In A Network – Hyperparameter Tuning, Batch Normalization And Programming Frameworks | Coursera. [online] Available at: <https://www.coursera.org/learn/deep-neural-network/lecture/4ptp2/normalizing-activations-in-a-network> [Accessed 23 June 2020].
- Ioffe, S. and Szegedy, C., 2020. Batch Normalization: Accelerating Deep Network Training By Reducing Internal Covariate Shift. [online] arXiv.org. Available at: <https://arxiv.org/abs/1502.03167> [Accessed 23 June 2020].
- Deeplizard.com. 2020. Batch Normalization (“Batch Norm”) Explained. [online] Available at: <https://deeplizard.com/learn/video/dXB-KQYkzNU> [Accessed 23 June 2020].