Nesterov momentum is different version of momentum update. It is also called Nesterov Accelerated Gradient.
In practice it works better than standard momentum (read abaout standard Momentum here https://marko-kovacevic.com/blog/momentum-in-deep-learning/ ).
The main idea is to look ahead before leap. If we know the velocity and direction of an object, we can predict its location in time T and calculate its gradient.
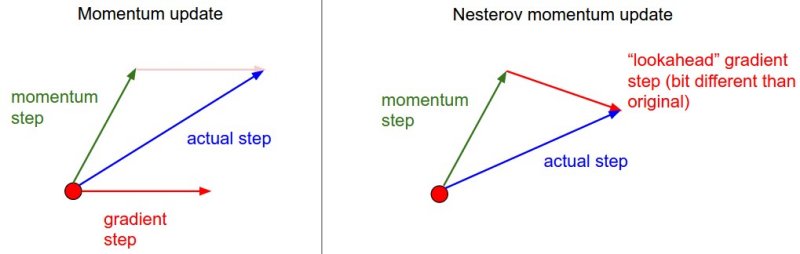
Instead of just blindly using momentum to keep going in the direction we were already going. Lets instead peek ahead by taking a big jump in the same direction of previous velocity and calculate the gradient from there. Then we use that gradient to update our velocity instead.
Mathematical Implementation
x_ahead = x + mu * v # evaluate dx_ahead (the gradient at x_ahead instead of at x) v = mu * v - learning_rate * dx_ahead x = x - v x_ahead - weight that is look ahead x - weight dx_ahead - gradient of x_ahead v - current velocity vector mu - momentum update
In practice people prefer to express the update to look as similar to vanilla Stochastic gradient descent or to the previous momentum update as possible.
Same formula but written to be similar as standard momentum:
v_prev = v # back this up v = mu * v - learning_rate * dx # velocity update stays the same x += -mu * v_prev + (1 + mu) * v # position update changes form
Weight update with standard momentum:
v = mu * v - learning_rate * dx
x = x - vVanilla weight update (without Momentum):
x = x - learning_rate * dxProgramming Implementation
Keras:
keras.optimizers.SGD(learning_rate=0.01, momentum=0.9, nesterov=True)Tensorflow:
tf.compat.v1.train.MomentumOptimizer(
learning_rate, momentum, use_locking=False, name='Momentum', use_nesterov=True
)https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/MomentumOptimizer
Thanks for reading this post.
References
- Cs231n.github.io. 2020. Cs231n Convolutional Neural Networks For Visual Recognition. [online] Available at: <https://cs231n.github.io/neural-networks-3/> [Accessed 20 April 2020].